Проблема несбалансированности данных возникает при решении целого ряда различных задач. Алгоритм предпочтительно выбирает класс, который преобладает. Критичной является ситуация, при которой миноритарный — с меньшим количеством данных — класс не предсказывается алгоритмом. Так, аналогичным является пример, когда на 10 000 (первый класс) выздоровевших выявлено 10 (второй класс) умерших, которые с субъективной точки зрения важнее, чем поправившиеся люди, но в количественном соотношении их в разы меньше.
Существует множество способов борьбы с ликвидацией классового дисбаланса: undersampling (прием, при котором удаляются примеры мажоритарного класса), oversampling (прием, при помощи которого создаются копии исходного фрагмента для получения необходимого объема для исследования), SMOTE (прием, позволяющий искусство сгенерировать данные). При использовании следующих приемов возникают некоторые проблемы. Так, если применять undersampling, то теряется информация о мажоритарном классе с большим количеством данных. Oversampling не всегда дает корректные результаты, поскольку не создает новой информации о миноритарном классе. Он ее дублирует. SMOTE не способен восстановить распределение миноритарного класса для решения поставленной задачи.
Представленные способы направлены на работу с данными. Они не применяются для самих алгоритмов, поэтому необходимо использовать модифицированные приемы, например, underbagging.
В случае задачи бинарной классификации, можно рассмотреть случай несбалансированной выборки с первым мажоритарным классом (Рисунок 1.а).
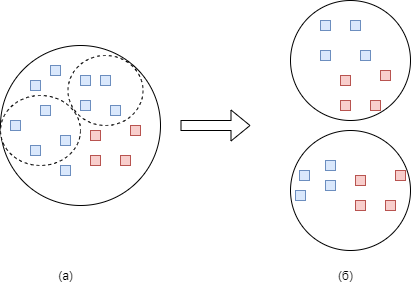
Рисунок 1 (а) – полная выборка. Синим отмечен мажоритарный класс, красным – миноритарный (б) – подвыборки, полученные с помощью случайного разбиения всей выборки
Формирование новых подвыборок (Рисунок 1.б) происходит следующим образом:- выбираются все n экземпляров миноритарного класса;
- случайным образом выбрирается n экземпляров мажоритарного класса без возвращения.
Таким образом, получается k новых подвыборок, где 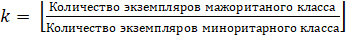 .
.
Каждая подвыборка служит набором данных для дерева решений (Рисунок 2.а). Обученные таким образом деревья решений являются лесом и используются для предсказания новых экземпляров путем голосования (Рисунок 2.б).

Рисунок 2 (а) – полученные подвыборки используются для обучения деревьев решений (б) – метка данных определяется голосами большинства деревьев
Деревья решений построены с помощью библиотеки Scikit-Learn [1] на языке Python 3.7.
Список литературы:- Pedregosa F. et al. Scikit-learn: Machine learning in Python //the Journal of machine Learning research. – 2011. – Т. 12. – С. 2825-2830.
- Thabtah F. et al. Data imbalance in classification: Experimental evaluation //Information Sciences. – 2020. – Т. 513. – С. 429-441.
- Wang S., Yao X. Diversity analysis on imbalanced data sets by using ensemble models //2009 IEEE symposium on computational intelligence and data mining. – IEEE, 2009. – С. 324-331.